
大數據時代背景下,數據的價值越來越受到社會各界的重視,各類基于大量數據的信息處理平臺不斷涌現,而如何實現對信息系統中數據規范化管理及使用,成為擺在眾人面前重要的問題。
信息系統,是指由計算機硬件、網絡和通訊設備、計算機軟件、信息資源、信息用戶和規章制度組成的以處理信息流為目的的人機一體化系統。簡單地說,信息系統就是輸入數據信息,通過加工處理產生信息的系統。
盡管信息系統根據具體搭建目的不同,需要收錄、使用的數據也不盡相同,但諸多系統都面臨一個共同的問題:平臺數據來源多樣,格式混亂,阻礙數據進一步使用。
因此,信息治理首先需要解決的就是數據不規范。今日,明朝萬達數據專家將以“基于字典樹的中文地址信息治理”為例,為您解讀數據處理的具體措施。
字典樹(單詞查找樹)應用背景
目前,信息系統中會記錄多種地址字段,包括單位地址、收件地址、寄件地址、住所地址等。字段中又包含區域信息(省、市、區/縣)和詳細信息(街道、街道號/小區名稱、樓號、樓層、房間號等)。以上地址信息可用于信息關聯、信息統計、信息分類等,具有很大的利用價值。
但是由于地址信息的來源存在多樣性、不可控性,導致大量的地址數據不規范,對系統合理充分利用形成了一定的阻礙。因此:
對地址信息進行標準化處理來提高地址信息的利用率,成為信息系統很重要的一項功能。

實現目標
01 區域信息治理
在地址信息中,提取或者還原省、市、區/縣信息
在地址信息中,提取區域信息以外的數據,并按照詳細規范進行數據格式化輸出。
處理過程
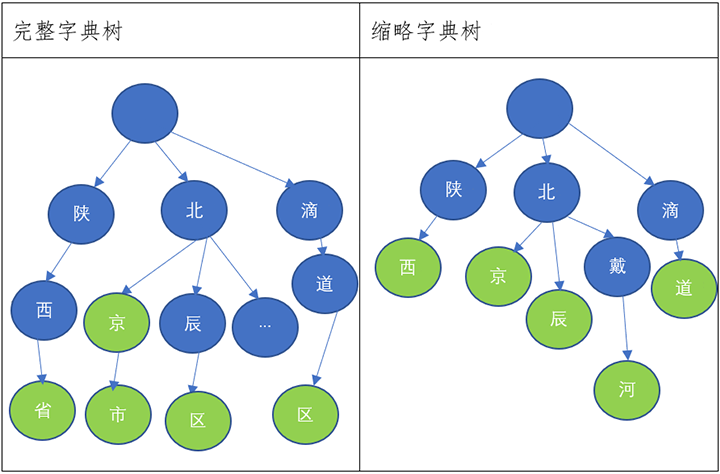
步驟一:使用最新的民政部行政區劃代碼,構建兩棵字典樹
※ 綠色代表葉子節點,葉子節點存儲完整的區域信息。
舉例:在完整字典樹中北辰區節點存儲:天津,天津市,北辰區;在縮略字典樹中西安節點存儲:陜西省,西安市&吉林省,遼源市,西安區&黑龍江省,牡丹江市,西安區。
步驟二:區域信息計算
※ 將地址信息在完整字典樹中從前向后進行掃描。
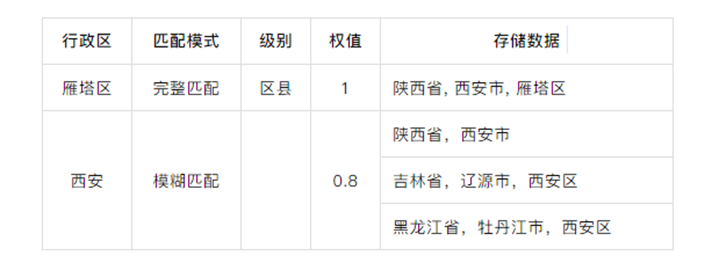
如果命中完整字典樹某一個分支,設置閾值1.0, 讀取保存的省市區縣信息;
※ 接著在縮略字典樹中進行掃描。
設置閾值為0.8,由于大部分地區會以某些城市名稱作為街道命名,故程序在處理過程中,向后探先探一位,如果包含“街”,“道”,“路”,“鄉”,“鎮”,“弄”,“坊”等,則將前面命中的一個分支作為詳細信息處理。如果包含“東”,“南”,“西”,“北”,“中”,“一”,“二”,“三”,“四”,“五”等,再向后探一位,如果包含“街”,“道”,“路”,“鄉”,“鎮”,“弄”,“坊”等也作為詳細信息處理。
※ 然后對各個省市縣信息進行閾值的累加。
※ 最后和完整字典樹掃描的結果進行相加,然后就會得出最終的區域信息。
舉例:處理地址信息,西安雁塔區科技7路4號
|
|
|
步驟三:詳細信息處理
※ 對詳細信息進行格式化處理。
使用xx街(路/道/弄等)xx號/小區xx樓xx單元/xx樓xx室,這樣的格式對詳細信息進行格式化。以上,便是基于字典樹的中文地址信息治理方式。
信息系統所收錄的地址信息經過字典樹處理后,利用程度得到進一步提高,同時提高了系統運作能力,促進集約化管理。
-----

作為中國新一代信息安全技術企業,明朝萬達專注數據安全、公共安全、云安全、大數據安全等服務,客戶覆蓋金融、政府、公安、電信運營商等諸多領域,其中在金融領域數據安全的市場占有率超80%。
明朝萬達始終將技術創新作為企業的立足之本,截至2020年6月,公司已申請 300余項發明技術專利,累計授權專利 近100項,多項技術填補了國內空白并達到世界先進水平。


