
新一輪科技革命已然開啟,5G、大數(shù)據(jù)中心、人工智能等領(lǐng)域發(fā)展如火如荼。而隨著這些新型科技在各行業(yè)內(nèi)應用普及,數(shù)據(jù)量級遞增,其價值也越來越受到全社會重視。
近年來,重大數(shù)據(jù)泄漏事件頻發(fā),對數(shù)據(jù)安全領(lǐng)域從業(yè)者是機遇更是挑戰(zhàn)。創(chuàng)新技術(shù)的應用和發(fā)展,為數(shù)據(jù)安全產(chǎn)業(yè)提供新的發(fā)展力,如AI在數(shù)據(jù)防泄漏中的應用。
那么,現(xiàn)行的數(shù)據(jù)防泄漏架構(gòu)是怎樣的?AI應用下產(chǎn)生的知識圖譜又是怎么一回事?讓我們跟著明朝萬達的數(shù)據(jù)安全專家一同來探討一二。
數(shù)據(jù)防泄漏問題
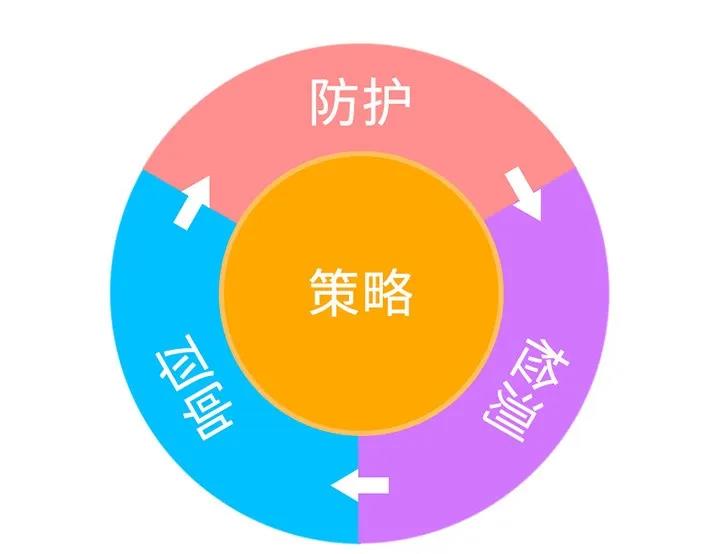
明朝萬達現(xiàn)有數(shù)據(jù)防泄漏架構(gòu)主要基于PPDR模型來實現(xiàn),PPDR由策略、防護、檢測、響應四部分機制組成。
其中,策略是核心,描述系統(tǒng)哪些資源需要保護;防護是加密機制等技術(shù);響應是應急策略;檢測是入侵檢測、數(shù)據(jù)防泄漏等技術(shù)。
數(shù)據(jù)防泄漏其核心能力就是內(nèi)容識別,識別出要保護的數(shù)據(jù)對象,然后對數(shù)據(jù)進行分類分級,最后根據(jù)客戶需求設(shè)置相應等級響應策略完成相應的數(shù)據(jù)防泄漏防護策略,從而達到保護系統(tǒng)安全和數(shù)據(jù)防泄漏的目的。
PPDR模型示意圖
-----
數(shù)據(jù)內(nèi)容識別技術(shù)發(fā)展
明朝萬達數(shù)據(jù)安全專家表示,當下數(shù)據(jù)內(nèi)容識別技術(shù)的發(fā)展已經(jīng)到了第三代。在數(shù)據(jù)內(nèi)容識別技術(shù)發(fā)展過程中:
第一代是基于規(guī)則匹配方法實現(xiàn),進而對識別內(nèi)容進行分類分級策略,該方法不具備智能性,無法做到準確分類分級,且局限性很大,不利于擴展到其他行業(yè)。
第二代識別技術(shù)是基于機器學習方法去實現(xiàn),該方法已具備初步的智能性,基于機器學習方法時,需要人工進行標注數(shù)據(jù),而后構(gòu)建復雜的特征對文本內(nèi)容進行分類,此方法已具備初步智能,但是需要耗費大量人力物力來進行數(shù)據(jù)標注和特征構(gòu)建。
第三代數(shù)據(jù)識別技術(shù)是基于知識圖譜來實現(xiàn),基于知識圖譜技術(shù)能利用正向反饋機制和自我學習兩種方式減少人工標注量,減少專家先驗知識和避免知識片面性,基于遠程監(jiān)督學習達到數(shù)據(jù)自動分類分級的目的,構(gòu)建出行業(yè)知識體系和領(lǐng)域內(nèi)知識圖譜,繼而擴展到其他行業(yè)領(lǐng)域。

數(shù)據(jù)識別技術(shù)發(fā)展歷程時間軸
-----
知識圖譜簡介
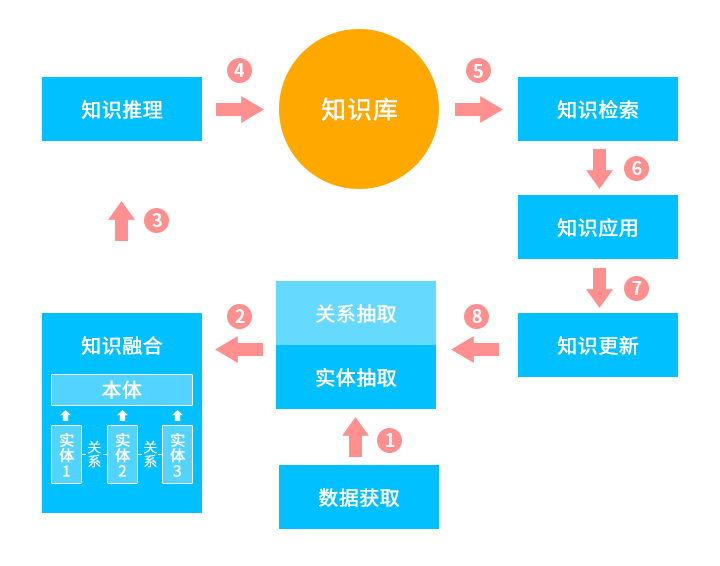
知識圖譜的架構(gòu)包括自身的邏輯結(jié)構(gòu)以及構(gòu)建知識圖譜所采用的技術(shù)結(jié)構(gòu)。
邏輯結(jié)構(gòu)分為數(shù)據(jù)層和模式層兩個層次,數(shù)據(jù)層由各個節(jié)點和邊組成,節(jié)點表示“實體”,邊表示實體間的“關(guān)系”,然后基于實體與關(guān)系經(jīng)過知識融合得到某一類的數(shù)據(jù)本體。模式層在數(shù)據(jù)層之上,是知識圖譜的核心,由數(shù)據(jù)層經(jīng)過提煉抽象得到。
明朝萬達數(shù)據(jù)安全專家解釋:知識圖譜由這兩部分結(jié)構(gòu)提供從“關(guān)系”的角度去分析問題的能力,利用模式層預測能力去分析問題,在分析問題的過程中可以根據(jù)分析的結(jié)果,反饋到數(shù)據(jù)層,利用正向反饋過程中的先驗知識在數(shù)據(jù)層加入正反向樣本使模型更加智能化,從而達到不斷自我學習目的,在完善與構(gòu)建知識圖譜的過程中通過不斷增加正反樣本來逐步減少人為的干預,使知識圖譜更加完善,最后構(gòu)建出領(lǐng)域內(nèi)知識。
知識圖譜構(gòu)建與應用流程圖
-----
知識圖譜簡介
基于知識圖譜的文本分類結(jié)構(gòu)圖
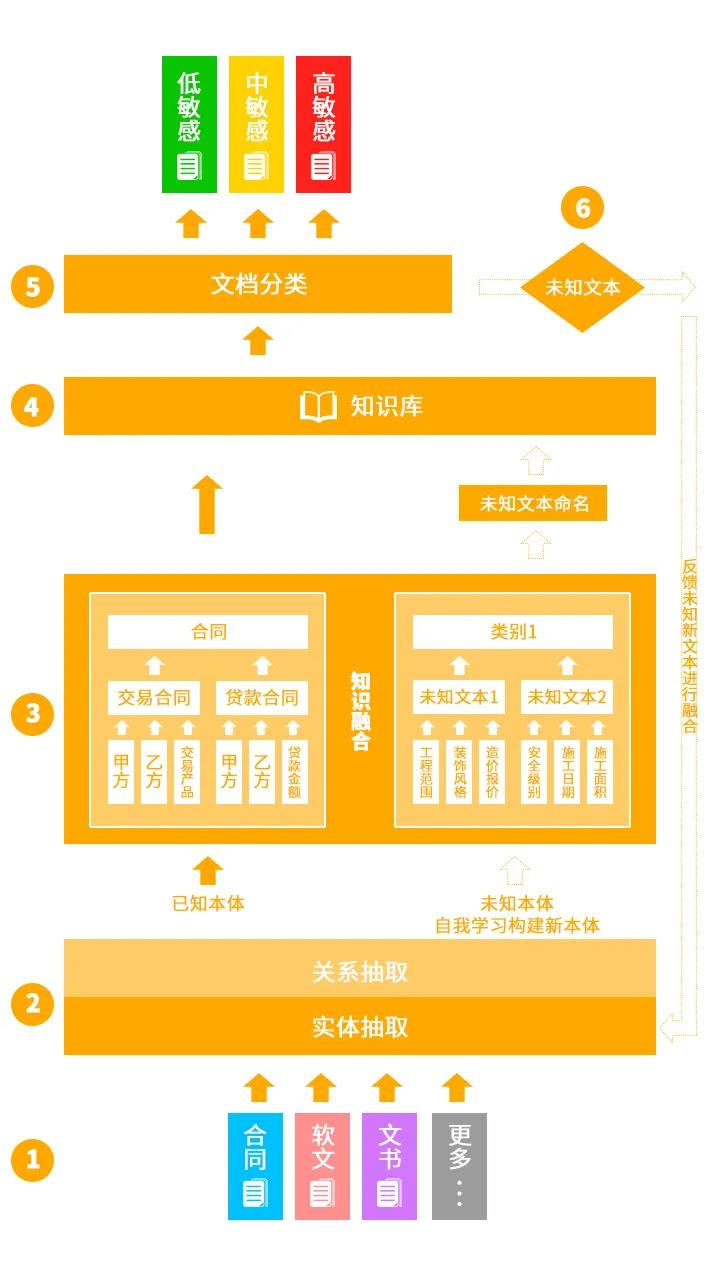
實施步驟:
本實例基于已知標簽文本的合同等類別和未知標簽文本的數(shù)據(jù)進行分類來對知識圖譜進行實施運用,大致分為數(shù)據(jù)輸入,實體關(guān)系等屬性抽取,知識融合和數(shù)據(jù)分類,然后對未知的文本進行正向反饋和自我學習,達到識別敏感數(shù)據(jù)分類分級的目的。

-----
意義與展望
知識圖譜作為人工智能的支撐基礎(chǔ),是人工智能的必經(jīng)之路,企業(yè)在發(fā)展技術(shù)的同時更應重視領(lǐng)域+知識圖譜發(fā)展。
在未來,技術(shù)不是公司的核心競爭力,多年積累的行業(yè)領(lǐng)域數(shù)據(jù)才是壁壘,要形成數(shù)據(jù)養(yǎng)育知識,知識反哺數(shù)據(jù),領(lǐng)域數(shù)據(jù)和知識圖譜應相輔相成,共同發(fā)展。知識圖譜因其能不斷自我學習和具備正向反饋機制可以很好遷移到其他領(lǐng)域。
知識圖譜擴展領(lǐng)域應用示意圖


